This is a working paper, the final version of which was published as Alaric Hall and Katelin Parsons, 'Making Stemmas with Small Samples, and Digital Approaches to Publishing them: Testing the Stemma of Konráðs saga keisarasonar', Digital Medievalist, 9 (2013), http://digitalmedievalist.org/journal/9/hall/.
Alaric Hall, University of Leeds
With a description of Winnipeg, Elizabeth Dafoe Library, ISDA JB6 1 4to and JB3 6 8vo by Katelin Parsons, University of Iceland
With relatively few scholars and a large number of texts whose manuscript transmission has yet to be mapped, Icelandic literature would benefit from efficient ways of establishing stemmas, to facilitate the study of literature, linguistics, scribal culture, and so Icelandic history more generally. This is also true for much medieval literature. Meanwhile, in saga-studies as in stemmatology generally, there has been little discussion of the role of sampling in textual criticism, even though most scholars must make heavy use of it. This article tests the viability of creating a stemma using a small sample of text by independently drawing a stemma of Konráðs saga keisarasonar, whose stemma was previously established by Zitzelsberger, and testing it against Zitzelsberger's. Although the approach has limitations, at worst it produces known unknowns which can then be resolved through targeted study; in practice it produces results very similar to Zitzelsberger's; and in some cases it actually allows us to improve on his work. The article also capitalises on internet publication rigorously to include all underlying data and to experiment with new, more transparent, ways of publishing stemmas; and to use digitised data to provide a new overview of the long manuscript tradition of medieval Icelandic romance sagas. Finally, it describes and filiates two new manuscripts of the saga identified in Winnipeg by Katelin Parsons. It concludes by sketching what the stemma of Konráðs saga can tell us about Icelandic scribal culture during its long post-medieval history.
sagas, textual criticism, stemmas, romances, iceland
This article has depended on the hospitality and assistance of the National Library of Iceland, the Stofnun Árnamagnússonar in Reykjavík and the Arnamagnæanske Håndskriftsamling in Copenhagen, and the research has benefited from the insight and benevolence of many scholars in these institutions. For the sharing of their unpublished work, help with technical problems, and discussions about stemmatology, however, I owe especial thanks to Andrew Wawn, Davíð Ólafsson, Haukur Þorgeirsson, Lenka Kovárová, Samu Niskanen, Sheryl McDonald, Silvia Hufnagel, Susanne Arthur, Teemu Roos, and Tereza Lansing.
Traditionally, stemmatic methods have been a means to the end of establishing which surviving manuscripts of a text are most representative of the text's putative lost ancestor, and thereafter to reconstruct the likeliest form of that lost text. This remains an important agenda in some scholarly traditions, and an appropriate response to certain scholarly questions and scribal traditions. However, postmodern approaches to medieval textuality rightly question the editorial goals of reconstructing lost originals of texts (see for historiography Bordalejo 2003, 39--65, and in a Norse context Wick 1996, 56--58). The stemma's usefulness in establishing what text an editor should put before their reader has, in many contexts, become dubious.
There remain, however, powerful arguments in favour of making stemmas aside from editing. As Ralph Hanna has put it, stemmas can be understood to describe `not a state, but a historical process' (1996 [1992], 116; cf. 10--11): they are a vital tool for understanding how a text developed and was transmitted---who copied from whom, how, when, where, and ultimately why (cf. Leslie 2012, esp. 150--51). Information of this kind may inform an editor's choice of manuscript for a `best text' edition, but its potential uses are far more diverse. In an Icelandic context specifically, being able to trace textual communities across the many centuries of scribal transmission would be an enormous contribution to our understanding of Icelandic literacy, literature, and society, with potential ramifications reaching well beyond the textual tradition itself. Likewise, scholars using manuscripts to study linguistic change benefit from knowing what forms a given manuscript's exemplar contained. Such analyses are beyond the scope of this article, but they indicate the importance of stemmatology as a scholarly method. Accordingly, in the final section below (5.3), I sketch some of the possibilities revealed by the stemma of Konráðs saga.
It is important to recognise that for the purposes of analysing `historical process', the best can be the enemy of the good: the challenges of establishing an unassailable stemma seem so great that it is tempting to produce none at all. And not without reason: while there is a tradition of scholars imagining that in textual criticism `close is not good enough', given that stemmas of medieval texts will virtually always involve lost manuscripts, it is in fact a delusion for us to imagine that we can, in most circumstances, achieve anything better (cf. Salemans 2010, 113--17 on subjectivity in textual criticism). Accordingly, the past research into the textual filiation of Icelandic romance-sagas listed below in section 1.3 is characterised by tentative claims and explicit approximations. Rather than imagining that stemmatology is about perfection, then, what is really important is for scholars to establish stemmas with a tolerable degree of probability, and there has been little effort previously to gauge what this might be, or to quantify it. This can provide a sound---if imperfect---basis for future research into the whens, whos, wheres and whys of scribal transmission. This article by no means has all the answers, but it is a beginning.
Old Norse studies enjoy a distinguished place in the history of textual criticism: the earliest known stemma was drawn for the Old Swedish Västgötalagen (Collín and Schlyter 1827--77, ii table 3; cf. Robins 2007, 93--94), while some of the pioneering work on computer-assisted stemmatology was undertaken by Peter Robinson on the Old Norse poem Svipdagsmál (Robinson 1989a, b; Robinson--O'Hara 1996). However, as Matthew Driscoll has recently emphasised, there has been little explicit discussion of the methods for establishing stemmas for Icelandic sagas---Driscoll's own postgraduate training `consisting in fact of only two words: "sameiginlegar villur" ' ('common errors', 2010, XXXXX n. 23; an important exception is Hast 1960, 8--13). Indeed, it is characteristic of Old Norse editorial practice that when Robinson co-edited the poem Sólarljóð, although he made his electronic data available online, the edition itself made no mention of his use of computer-assisted methods in establishing its textual history (Larrington--Robinson 2007, 291--94).
This paper contributes to remedying the lack of methodological discussion on Old Norse-Icelandic stemmatology by working to establish transparent, verifiable, and efficient methods for filiating the manuscripts of Icelandic sagas, while undertaking what is to my knowledge the first independent verification of a full saga-stemma. This is not to say, of course, that there has been no verification of stemmas previously: the painstaking editorial work of the last century epitomised by the Editiones Arnamagnaeanae series and, more recently, the Skaldic Poetry of the Scandinavian Middle Ages project, has led to a progressively better understanding of our Old Norse manuscript records, and has accordingly involved reassessments of past textual criticism. Konráðs saga keisarasonar, the focus of this paper, is a case in point: Gustaf Cederschiöld provided a stemma for five early manuscripts of the saga (1884, clvi--clxxiv) which Zitezelsberger, en route to his meticulous 1987 edition, both revised and extended nearly a century later in a series of articles producing one of the best documented stemmas of any Icelandic saga (1980, 1981, 1983). Nevertheless, complete stemmas, including every surviving manuscript of a given saga, have seldom been produced (researchers focusing instead on the earliest manuscripts), and no-one has undertaken an independent verification of a stemma on this scale.
The transparency and verifiability of my work arises from a couple of simple features which capitalise on electronic publication:
|
Figure 1. Core spreadsheet of data used in this article, based on Kalinke and Mitchell 1985. This provides an integrated assemblage of data used. |
My core aim, however, is efficiency. This is perhaps a more surprising goal than transparency; it is, at any rate, rarely mentioned in humanities research publications, perhaps because it is thought to conflict with the more important demand of scholarly rigour. Thus the exciting deployment of computer analysis in stemmatology in recent years has focused on producing ever more thorough investigations (Bordelejo 2003, 39--65; Robins 2007). To quote from Bordalejo's online manifesto for what she calls the `New Stemmatics',
This makes sense, since comparison of large datasets is something which software is much better at than people. This article takes a different perspective, however. Pre-twentieth-century Icelandic literature is a field characterised by large numbers of texts surviving in large numbers of manuscripts, transmitted scribally from as early as the twelfth century to as late as the twentieth. Meanwhile, interest in the post-medieval life of medieval Icelandic sagas is growing rapidly, by turns reflecting and provoking leaps forward in the digitisation and dissemination of Icelandic manuscripts, key examples being the ongoing digitisation and free-access publication of material via the Medieval Nordic Text Archive, the Skaldic Poetry of the Scandinavian Middle Ages project, handrit.is, and the related Stories for All Times project. Working out how to map efficiently the complex scribal traditions to which our surviving manuscripts attest would be of great benefit to this emergent research---and to medieval studies more generally---transforming our understanding of what individual manuscripts mean as cultural and linguistic evidence. In this article, I address two main opportunities for efficiencies:
- Analysis aims to obtain as comprehensive a view as possible of the relations among the witnesses
- Analysis is based, as far as possible, on all data
- Quantitative tools, typically computer-based, are employed in the analysis.
It is important to be clear about the limitations of the present study. As Cisne, Ziomkowski and Schwager have pointed out, `philologists reconstructing ancient texts from variously miscopied manuscripts anticipated information theorists by centuries in conceptualizing information in terms of probability' (2010, 1). The tools available for assessing probability---whether mathematical techniques or software to implement them---have advanced dramatically since the days of Carl Schlyter and his more famous contemporary Karl Lachmann. Philologists' training in mathematics and computing, however, frequently has not; and this is certainly so in my case: I am not, in short, qualified to address sampling in stemma-making in the way that this deserves. However, past scholars in the field have generally avoided this issue simply by concealing their use of sampling: despite their limitations, then, my exploratory discussions of problems in stemma sampling should be a step forward, underpinning and provoking future discussion and interdisciplinary collaborative research. Accordingly, the research presented in this article underpins further experiments with other datasets, which aim progressively to refine and define a reliable, transferable methodology (see Hall forthcoming; Hall and McDonald forthcoming).
The saga which this article uses as its case-study, Konráðs saga keisarasonar (the saga of Konráður the Emperor's son), is an Icelandic prose romance from around the fourteenth century (cf. Kalinke and Mitchell 1985, 75). As I have discussed, Zitzelsberger built on the work of Cederschiöld to construct one of the best documented stemmas of an Icelandic saga (the main rival among non-translated Icelandic romances being Slay 1997). So-called medieval popular romance of the kind represented by Konráðs saga has recently been attracting growing interest across Europe (see Driscoll 2005; Hall, Haukur Þorgeirsson, Beverley, et al. 2010, 56--58), and as a genre well represented in post-medieval Icelandic manuscript production it is an ideal basis for a case-study in tracing scribal transmission through the longue durée of Icelandic scribal culture. This section focuses on providing a new, data-led overview of that scribal culture, and establishing the representativeness of Konráðs saga within it.
There has never been a thorough analysis of the distibution of Icelandic romance-saga manuscripts over time. My digitisation of Kalinke and Michell's 1985 survey of these manuscripts, however, enables a new overview of the field, extending the initial survey by Glauser (1994a/b). By Kalinke and Mitchell's count, the sagas survive across a total of 811 manuscripts, each appearing on average in 30 manuscripts. Their work is not without occasional mistakes: thus their list of Konráðs saga manuscripts includes Lbs 2497--98 8vo, when this is actually Gunnlaugur Þorðarson's 1859 printing of the saga bound into a two-volume manuscript collection of other romance-sagas---a fascinating combination, but not one further addressed in this acticle. Generally, though, Kalinke and Mitchell's figures are an underestimate, due to a trickle new further manuscripts coming to light since 1985 (epitomised by the new manuscripts described in section 4.1 below), and to occasional accidental omissions, not only of manuscripts but of sagas (Nikulás saga leikara, omitted by Kalinke and Mitchell, is now known to have been composed during the Middle Ages: Sanders 2000, 17, 21; cf. Kalinke 1994, 120 n. 5 on Víglundar saga). Their work is amply reliable, however, for the purposes of an overview, and the analyses in this section use their bibliography as it stands.
The following network graph (Figure 2) summarises the manuscript record for the genre, showing which romance-sagas co-occur in manuscript with which (where they do---instances of romance-sagas appearing on their own in manuscripts are not shown). The data is slightly messy: it does not account for the breaking up of manuscripts which were once whole, or the binding together of manuscripts which were once separate. The graph also conflates the data from manuscripts dating from the thirteenth through to the twentieth centuries, predominantly reflecting the contents of eighteenth-century manuscripts, which dominate the dataset. Still, it provides a convenient conspectus.
The graph shows sagas as nodes and the manuscripts in which sagas co-occur as edges. It was created using the `force' algorithm in the open-source graph-manipulation software Gephi: the more often one saga co-occurs with another in manuscript, the more strongly those sagas are drawn together. The larger a node is, the more manuscript witnesses of that saga there are; likewise, the thicker an edge, the more manuscripts containing both sagas there are.
 |
Figure 2. Network graph of the manuscript attestation of romance sagas. |
Figures 3 and 4 show the distribution of romance-saga manucripts over time, with numbers of surviving manuscripts increasing until around the Reformation, at which point it dips, followed by a steady rise into the eighteenth or nineteenth century, and rapid decline in the twentieth. The differing transmissional histories of local and translated Icelandic romances suggested by my network analysis are also apparent here: assuming that manuscript survival is representative of production, following an early lead, translated romances became less popular than local compositions, with a major decline in relative popularity in the nineteenth century. The divergent history of local and translated Icelandic romances might reflect readers turning to printed versions of translated romances from the eighteenth or nineteenth century, but perhaps also reflects a generic distinction along the lines of `popular' and `highbrow' romance, with `popular' romances widening their lead in market share in the nineteenth century (cf. the case studies of manuscript production in this period afforded by Glauser 1994a, 1994b; Driscoll 1997; Davíð Ólafsson 2009; Lansing 2011, 52--78). This would be consistent with the size of manuscripts, a characteristic which has been analysed in detail for Hrólfs saga kraka by Lansing (2011, 73--78). Lansing's work on this was very detailed, but since most library classmarks indicate whether an Icelandic manuscript is folio, quarto, or octavo, my spreadsheet of romance-saga manuscripts enables us roughly to trace the overall trajectory of manuscript-size for the whole corpus of medieval romance-sagas (scoring folios as 2, quartos as 4 and octavos as 8, so that a low score represents a large manuscript: Figure 5). The sixteenth-century crash in the size of manuscripts of translated romances is an outlier: the century is represented by only one, octavo manuscript. With the relatively small dataset available here, it seems inappropriate to try to correct for this statistically: the overall trend is clear. Overall, assuming that the figures are not caused by selective preservation of large, early manuscripts, Icelandic romance shows a consistent diminution (more marked for local compositions than for translated romances) from the seventeenth or eighteenth century. Whatever its motivation---likely causes include lower cost and greater portability, as manuscript production became more widespread among and more closely associated with poorer sections of society---this new trend for smaller manuscripts again indicates a shift in scribal culture.
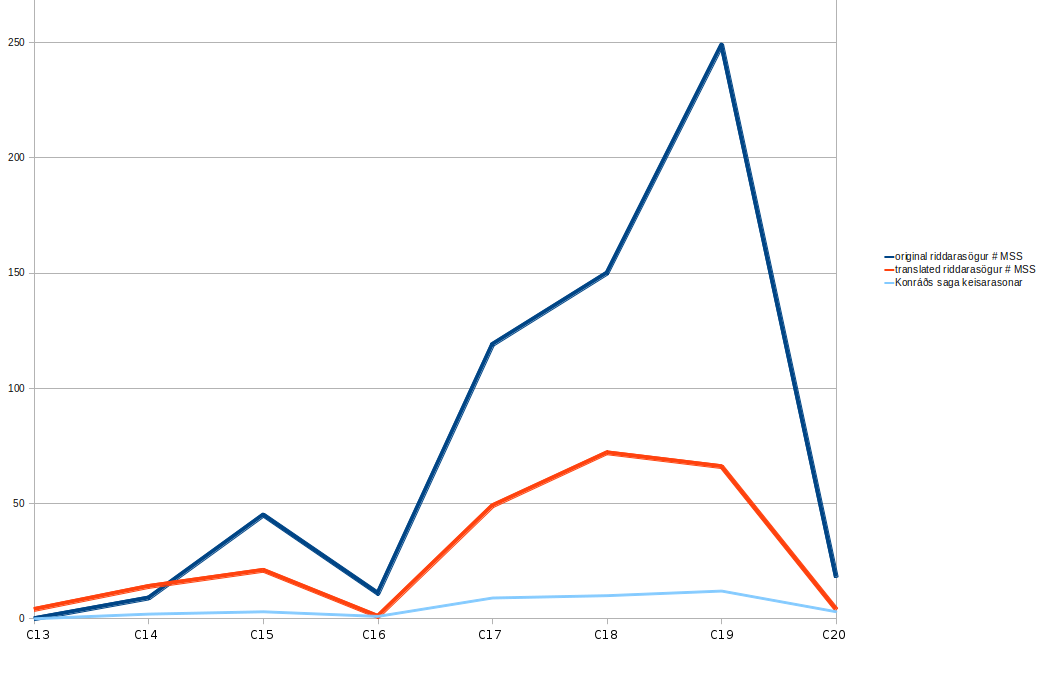 |
Figure 3. The number of manuscripts containing romance-sagas, by century (including only the 729 in Kalinke and Mitchell 1985 which can readily be assigned to a particular century). |
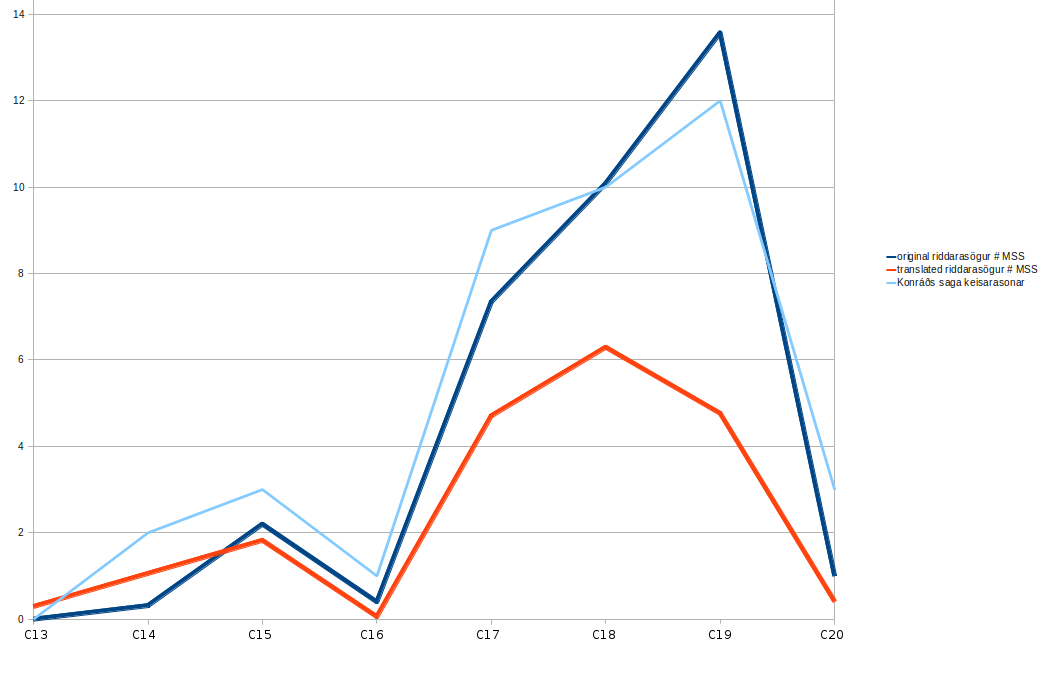 |
Figure 4. The average number of manuscript witnesses of a romance-saga, by century (including only the 729 in Kalinke and Mitchell 1985 which can readily be assigned to a particular century). |
 |
Figure 5. The size of manuscripts containing romance-sagas, by century (including only those in Kalinke and Mitchell 1985 which can readily be assigned to a particular century and whose size is known). |
As Figure 4 shows, Konráðs saga is for most of its history slightly better attested than the average Icelandic romance-saga (against an average of 33 manuscripts, it survives in a total of 48 manuscripts and fragments, including an unusually large number of medieval ones), but is clearly a good representative of the overall trajectory of survival. It will be clear that Icelandic romance-sagas---particularly those composed in Iceland---represent a large and cohesive corpus, widely copied and well attested over a long period, with important potential for insights into Icelandic literary culture during this period. Most importantly for present purposes, Konráðs saga seems unremarkable, situated comfortably near the core cluster of networked manuscripts, with a representative distribution of manuscripts over time.
For the thirty-five or so romances which were composed in medieval Iceland, a century of study has produced more or less complete and explicitly argued stemmas for three besides Konráðs saga (which, where practicable and appropriate, I have rendered as dendrograms and linked to below):
 ) icon. My manuscript transcriptions (described below in section 2.3) can be seen by clicking on the call number of each manuscript. Text in red shows alterations from the parent manuscript. Ellipses in curly brackets ({...}) indicate omissions from the parent. Otherwise, transcription principles are largely as described below in section 2.3 (italicised expansions in my original transcriptions are rendered here in Roman type for ease of reading; manuscripts' line- and page-breaks are only replicated insofar as they force a word-space). Where not otherwise stated, manuscript provenance is derived from Zitzelsberger (1981, 1983) and handrit.is.
) icon. My manuscript transcriptions (described below in section 2.3) can be seen by clicking on the call number of each manuscript. Text in red shows alterations from the parent manuscript. Ellipses in curly brackets ({...}) indicate omissions from the parent. Otherwise, transcription principles are largely as described below in section 2.3 (italicised expansions in my original transcriptions are rendered here in Roman type for ease of reading; manuscripts' line- and page-breaks are only replicated insofar as they force a word-space). Where not otherwise stated, manuscript provenance is derived from Zitzelsberger (1981, 1983) and handrit.is.
  |
Figure 6. Dendrogram of Zitzelsberger's stemma of Konráðs saga (1980, 1981, 1983). Texts omitted from my own survey are coloured grey. |
In terms of the sophisticated graphic renderings now possible, my HTML format is primitive. A more advanced implementation would draw the stemma's content directly from a central database and highlight differences between texts and their exemplars automatically, whereas for the purposes of this article I have duplicated the data contained in my core spreadsheet, and marked up textual variation manually. Meanwhile, for the reader, my stemma is less intuitive than a tree diagram, nor can it readily represent texts with multiple exemplars such as MS F (which traditional stemmatology would refer to as `contaminated' texts): these simply have to be included in more than one branch of the stemma, with a note to this effect. To this extent, my HTML stemma is markedly inferior to the more elegantly rendered, hyperlinked stemmas afforded by the Skaldic Poetry of the Scandinavian Middle Ages project, such as their stemma of Óláfs saga helga in sérstaka. However, the coding of my example is hopefully simple enough to be readily future-proof, and when working in Western languages with their left-to-right scripts, the horizontal orientation of the tree makes it easy to integrate full call-numbers for manuscripts and other information in a way that is difficult with vertically orientated tree diagrams. Moreover, in my stemma, by revealing transcriptions, the user can relatively easily compare the actual texts on which the stemma is based, and so form their own judgement as to the reliability of the stemma. In traditional publications, this evidence would normally be present, if at all, in the form of lists of representative readings, which readers can generally only interpret with the greatest concentration. Where I have posited lost manuscripts, I have also reconstructed their text---not in the belief that the reconstruction is completely accurate, but as a tool both for the clear expression of the arguments implicit in the stemma, and as a means to ensure rigorous analysis on my own part. Although still far from perfect, the stemma here takes a large step towards a more intuitive and transparent mode of publication, and will hopefully provoke debate and experimentation with other innovative methods.
As a side benefit, the HTML stemma also makes it relatively easy to browse the different versions of a text and get an impression of how in the course of scribal transmission texts can take radically different forms through incremental small changes. This gives a sense of how versions which might otherwise be understood as different recensions, produced by a single, creative intervention in the textual tradition, or perhaps as the re-prosification of a rímur, can also arise as the result of a more gradual process of change. Presenting data transparently in this way also means that as new manuscripts of the text are discovered---and as I discuss below (section 4) they still can be---researchers can easily filiate them without, at least initially, needing to return to other manuscripts.
The key question for efficient stemma-making is what kind of sample of a text is needed to make a stemma of a given reliability, a question which has enjoyed remarkably little study. The editors of the romance-sagas mentioned above do not discuss sampling, but they cannot have considered every single variant in every manuscript of the sagas they studied: the task would have been virtually insurmountable. They must have sampled the texts---perhaps methodically, perhaps haphazardly. One of the few explicit discussions in the field is by Sture Hast, in his analysis of the Íslendingasaga Harðar saga. Hast drew his stemma on the basis of sample passages, ignoring variants which he considered likely to represent convergent innovations (1960, 8--11). Thus sampling of two kinds has tacitly been fundamental to saga-editors' stemmas, and no doubt many others': the sampling of sections of texts, and the sampling of kinds of variants. I discuss text-sampling in this section and variant-sampling later, in section 2.5.
Counting in the standard edition (Þórhallur Vilmundarson and Bjarni Vilhjálmsson 1991, as digitised by Sæmundur Bjarnason et al. n.d.), Hast himself used sections of 1940, 2016 and 1431 words from, respectively, the beginning, middle and end of Harðar saga (the saga itself is 19,109 words long, so in total Hast sampled about 28% of the saga). The samples are coterminous with folios in the principle manuscript, but beyond that I am not aware that there was any particular rationale for Hast's choices.
In the only experimental study of sampling in stemmas of which I am aware, Spencer, Bordalejo, Robinson and Howe examined fifty-eight manuscripts and early printed editions of Chaucer's Miller's Tale. They tested the similarity of stemmas based on samples to stemmas based on the complete dataset (itself tested using bootstrap analyses; 2003). They divided the complete dataset (by my count, 5275 words in the Ellesmere manuscript) into 3958 `characters' (sites of possible textual variation, usually one or two words), 1540 (39%) of which turned out to show `parsimony-informative' variation (variation of a kind suitable for textual criticism). They found that `even with the smallest subset size [123 characters, of which 48 were presumably parsimony-informative], the stemmata are more similar than would be expected by chance' (2003, 413) and concluded that samples larger than about 1000 characters (of which 390 were presumably parsimony-informative) made little difference to the stemma: in this dataset, sampling about 1300 words would be sufficient to create a stemma almost as reliable as one based on the whole text. Thus Spencer, Bordalejo, Robinson and Howe hint at an order of magnitude for reliable sampling: around 1300 words, or around 390 parsimony-informative characters.
It is important to say `1300 words' or `390 parsimony-informative characters' rather than `25% of the text'. There has never, as far as I am aware, been any research into whether the rate at which a scribe produced variants is proportional to the length of the text they are copying. But, a priori, it seems likely that a scribe will generally introduce changes to a text at a rate unrelated to the overall size of a text. One can of course envisage various possible reasons why scribal variation might be related to text-length: a scribe aiming for an exact copy of a text might copy a short one diligently and accurately but flag while copying a longer one; a scribe aiming to revise a text might alter a short one in detail but a long one more lightly (saving effort by falling back into mechanical copying) or more drastically (saving effort by cutting a significant proportion). But it seems a reasonable hypothesis that a sample that is big enough to establish the stemma of a text of, say, 5,000 words in a given scribal culture should also, by and large, be big enough to establish the stemma of a text of, say, 50,000. (It also follows, incidentally, that some texts in some scribal cultures may inherently be too short ever to enjoy a reliable stemma: a fundamental methodological problem which would bear further investigation; cf. Taylor 2007, 732.) If the figure suggested by the Miller's Tale is at least in the right ballpark, this hints that Hast analysed about four times as much text as he needed to to establish a reasonably reliable stemma for Harðar saga.
The comparison with the Miller's Tale is, of course, merely a hint. The Miller's Tale is a very different text from an Icelandic prose romance, not least because it is in verse; and the scribal culture of late medieval England, which included a measure of secular, commercial, urban production, was quite different from any of the various scribal cultures which produced Icelandic romances during their long manuscript transmission. There are technical complications in transferring Spenser, Bordajelo, Robinson and Howe's conclusions to sagas too:
Despite the methodological problems, then, it is clearly worth at least exploring the possibility that relatively small samples of saga-manuscripts can produce sufficiently reliable stemmas. My approach here works on the principle that omissions (rather than mistakes) caused by small samples are methodologically acceptable, as long as the researcher is conscious of the limitations of the information, and sensitive to the possibility that anomalous looking texts might represent poorly sampled texts from multiple exemplars. Indeed, it needs to be remembered that stemmas are always provisional. Stemmas are necessarily constructed on a principle of parsimony: we look for the stemma which involves the smallest number of independent innovations, inferring as few lost manuscripts as possible. Thus one manuscript may appear to be the parent of another but it is always implicit that the true parent may have been a lost, identical copy. The smaller the sample used, the more likely one manuscript is to appear to be identical to another, and therefore potentially in a parent/child relationship, when fuller sampling might show them instead to be in some other close relationship, so the use of small samples makes it particularly important to recognise this kind of provisionality. That said, the attention to detail which my small samples promoted actually led me to reconstruct more lost manuscripts than Zitzelsberger, because I sometimes found that one manuscript identified by Zitzelsberger as the child of another in fact contained more conservative readings than its putative parent, thus necessitating the conclusion that the manuscripts were in fact siblings, descended from a lost common source (see section 3.4). It is not necessarily the case, then, that bigger samples lead human researchers to more refined results.
My aim was independently to test Zitzelsberger's stemma by creating my own. Where Zitzelsberger's work (1980, 1987) provided transcriptions of manuscripts, either directly or through his critical apparatus, I used these. Repeating Zitzelsberger's manuscript sigla for convenience, these manuscripts were:
I took two samples from each manuscript, one of 112 words from the beginning, and one of 205 from the end (counting in Cederschiöld 1884). In terms of length, these choices were, in the jargon of market research, a `judgement sample'---that is, made largely on my own pragmatic and intuitive assessment of what was likely to be both efficient and effective, informed by the research discussed in section 2.2 above; my own prior work on saga-stemmas (cf. Hall 2005, 10; Hall forthcoming; Hall and McDonald forthcoming); and the identification of clear narrative units that were fairly likely to be stable in transmission. Thus the first passage runs from the beginning of the saga to the end of the description of Jarl Roðgeir; the second passage runs from the description of the descendants of Konráður and Matthildur to the end. Taking text only from the beginning and end of the saga is problematic: it is prone to the problems of omission discussed in the previous section; openings and closings are especially likely to contain formulaic language, and might therefore be prone to convergent innovation with other manuscripts; and conventional wisdom has it that scribes are more likely to behave in uncharacteristic ways at the beginnings and the ends of texts. In my view, however, these disadvantages are outweighed by the considerable pragmatic advantage that it is easy to define, and indeed find, the beginning and the end of a saga: however much variation different versions of the text may exhibit, they will, unless fragmentary, always have a beginning and an end. (For experimentation with a wider range of samples, however, see Hall forthcoming; Hall and McDonald forthcoming.)
Ideally, the transcriptions on which my stemma was based would have been undertaken according to the exacting standards of the Medieval Nordic Text Archive (Haugen 2008), which besides rigorous accuracy would have the advantage of laying the foundation for a diachronic text corpus which could possibly be used for linguistic research as well as stemmatology. However, transcription to this standard was not practicable for the task in hand. The manuscripts of Konráðs saga keisarasonar exhibit a wide variety of scripts, hands, and spelling conventions, including variation within the work of individual scribes; several are also hard to read or even, at times, illegible due to damage. Therefore, while making a general effort to represent the manuscript forms closely in my transcriptions, I did not agonise in individual cases over the transcription of ambiguous letter forms where these made no difference to the sense, aiming instead for consistency of handling each manuscript. Thus I tended to establish a single approach for each manuscript as to whether a graph was better to be transcribed as i or í, ij or ÿ, ö or ő; ǫ and ỏ were both transcribed as the ǫ of standardised Old Icelandic. My transcriptions expanded abbreviations, and it was sometimes unclear what form the scribe would have used if he had written an ending in full (principally whether Old Norse -ir would be -ir or -er). Each missing or illegible letter is represented with $ (obviously at times the number of $s is an estimate), while uncertain readings are marked with [?]. Once I was familiar with the text, an easily legible manuscript like AM 524 4to, illustrated in Figure 7, would take me half an hour to transcribe; 33 transcriptions, totaling around 13,000 words, took around 27 hours in total (a more experienced palaeographer, a more fluent speaker of Icelandic, or a better typist would doubtless have worked quicker). Inevitably, I formed an initial impression of the manuscript filiation while transcribing and I often identified and checked possible transcription errors while subsequently analysing the manuscripts' filiation. In practice, therefore, transcription and analysis of texts were to some degree recursive rather than sequential processes.
 |
 |
Figure 7. Sample manuscript transcription: AM 524 4to. |
At the beginning of this project, I had hoped that phylogenetic software, of the kind which is now being used widely in stemmatics, would provide a sufficiently reliable method for stemma construction that human brainpower could largely be devoted instead to interpreting the data provided by the stemmas. In the event, as I discuss below, it became clear that human input dramatically improved the reliability of analyses (cf. Hanna 2000 regarding the Canterbury Tales); but the use of software was nonetheless an intrinsic and important part of the process of human analysis (a finding similar to the experiments of Niskanen 2009, 6--7). This section discusses the degree of success achieved through the software analysis. Since these processes are still relatively unfamiliar to most humanities scholars, I give a fairly detailed, step-by-step account of my methods, giving access to the latest versions of the files I used while the work was in progress. Needless to say, it is possible that with larger datasets, improved data-handling, or different software, software-based analyses could provide more accurate results than those achieved in this study, and this would be a fruitful area for further research (cf. Hall forthcoming; Hall and McDonald forthcoming).
The most popular software in the field of stemmatics is currently PAUP* (whose name stands for Phylogenetic Analysis Using Parsimony). Roos and Heikkilä developed an algorithm for scoring the similarity of two stemmas and tested the stemmas produced by PAUP* and a range of other software against constructed textual traditions whose true stemmas are known. Roos and Heikkilä's main constructed tradition involved a 1,200-word text with 67 manuscripts (of which 37 were made available for analysis, the others representing lost texts; 2009). Unlike the Canterbury Tales Project, Roos and Heikkilä assumed that spelling variation was parsimony-informative; in their mark-up, there were 1209 characters, all considered parsimony-informative, with an average of 3.8 variants per character. To readers accustomed to UK university grading scales, their scoring system will be uncannily familiar: while 100% is a perfect match, 75% represents the best achieved in practice; 60% is about average; and 50% is the kind of score that is achieved simply through random inputs (2009, 422 table 3). Tested against Roos and Heikkilä's dataset, PAUP*'s parsimony program emerged with 74.4%. It is worth noting that although Roos and Heikkilä did not attempt a purely manual reconstruction of the stemma, it is not to be assumed that it would necessarily have achieved greater accuracy. For pragmatic reasons I chose PAUP*'s main competitor, Phylip, and specifically the program Pars (Felsenstein 2005; Felsenstein 1986--2008; cf. 1989). Like PAUP*, Pars takes its name from its parsimonious principles of filiation: it seeks to minimise the number of branches in the tree, thus conforming to traditional stemmatological principles, making it a closely comparable piece of software (cf. Misra, Blelloch, Ravi and Schwartz 2010, 370). The attraction of Pars over PAUP* was that it was free, open-source, and readily available not only for proprietory operating systems but also for the open-source operating system Linux, none of which presently holds for PAUP*. The main disadvantage is that whereas PAUP* can handle up to sixteen different character states, Pars can handle only eight, which meant that the data had to be divided into more characters than was sometimes convenient. (It is also relatively slow, but this was not a problem with the small datasets employed here.) Pars has not, as far as I am aware, previously been tested in stemmatics, but my own experiments using it with Roos and Heikkilä's dataset suggested that it could be as powerful as PAUP*.
I made thirty-five of the transcriptions into a spreadsheet of aligned readings, giving 98 characters. (See Figure 8 for this spreadsheet and other files discussed here.) Variants were numbered, with an average of 6.6 variants per character (thus 652 different variants in total). For reasons discussed in the next section, I aimed to capture all lexical variation, but no spelling variation, while, for efficiency of alignment, maximising the number of variants per character. Where a character could not be read (either due to illegibility or the incompleteness of the manuscript) I made use of Pars's facility to mark it as ?, indicating uncertainty. Variant alignment was a laborious process (taking about 10 hours) but was not only necessary for Pars analysis, but also invaluable as an aid to subsequent human analysis of the data. (Again, this was a recursive process, with initial analyses undertaken before all the manuscripts had been transcribed; in the event, some corrections, and the last seven manuscripts, along with the new manuscripts discussed in section 4, were never included in the spreadsheet. It proved quicker to filiate these final manuscripts simply by human analysis, a process facilitated by the fact that in some cases their existence had already been predicted by earlier analyses.) I then converted the spreadsheet to a file formatted for Pars analysis. I ran this through Pars, using the default settings, and produced an unrooted stemma using the Phylip programme Drawtree.
It does not require a long perusal to conclude that this is unlikely to be an accurate stemma: the earliest manuscripts (generally those with labels beginning in Holm and AM), for example, appear in two widely separated groups and never appear as exemplars of other manuscripts. I subsequently quantified the similarity of this stemma to Zitzelsberger's using Roos and Heikkilä's algorithm (2009: 420--21): I encoded the Pars stemma and Zitzelsberger's stemma as appropriately formatted .dot files; manuscripts not present in the Pars stemma filiated by Zitzelsberger at the end of branches were not included in this encoding of Zitzelsberger's stemma. I applied the algorithm using Roos's C program Rankdistance. The Pars stemma scored 62%: better than random, but not enormously. Although, as I argue below, the low score can partly be accounted for by errors in Zitzelsberger's stemma, it is clear that different approaches would be needed to produce a reliable stemma using a computer alone. However, the Pars stemma, like the spreadsheet underlying it, was nonetheless invaluable to my own subsequent analysis: it shows a number of clear clusters, and while the precise internal relations within these groups were often implausible, they provided helpful starting-points for grouping manuscripts which needed to be filiated.
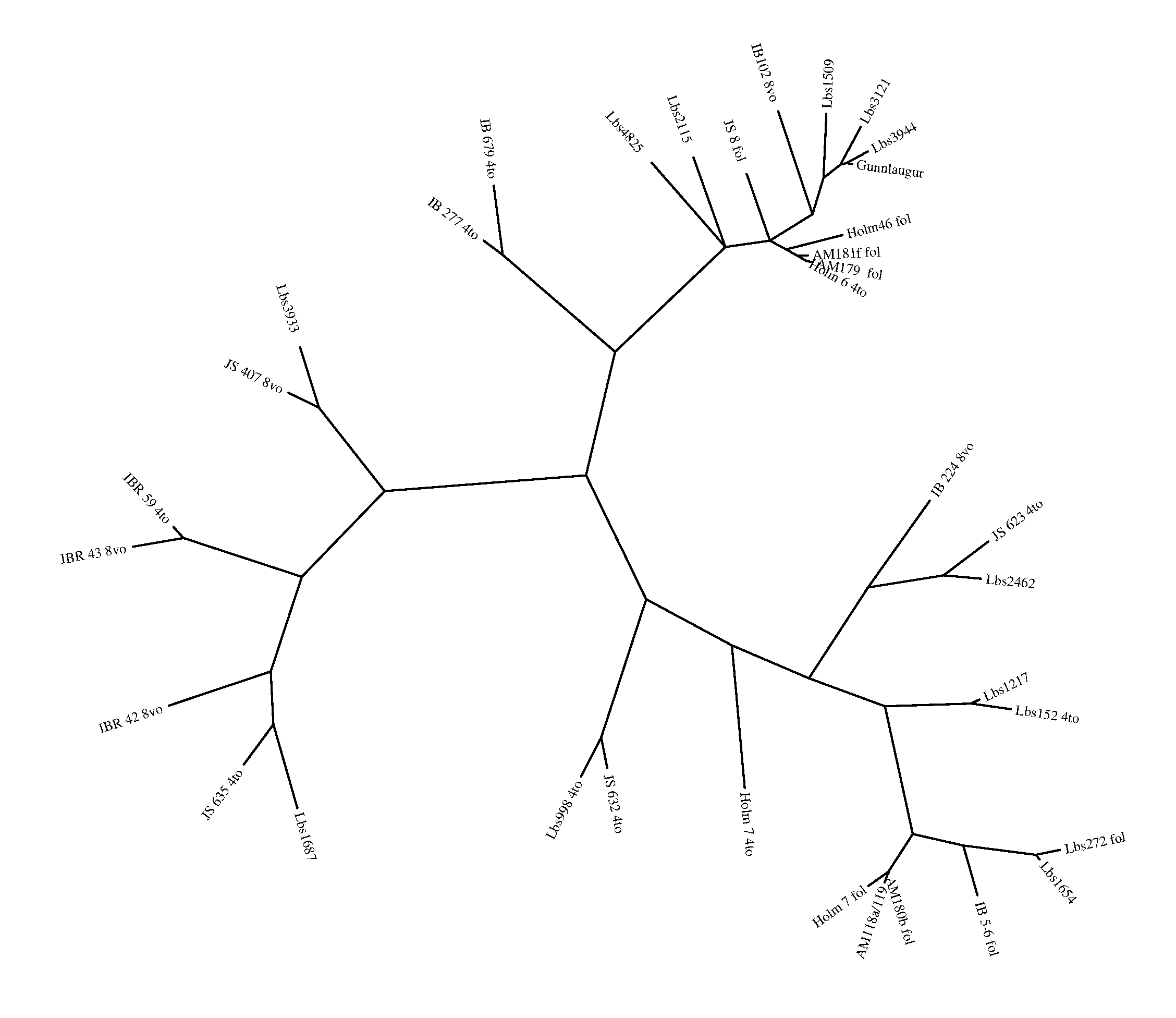 |
Figure 8. Spreadsheet of aligned readings and resulting unrooted stemma of 35 texts of Konráðs saga (working files, representative of the research process)
|
However, Old Norse scholars are usually more selective regarding lexical variation than I was. As in Hast's work, discussed above, it is usual to exclude so-called minor variants---words which are liable to show independent common innovation. These are often function words such as the relative particles sem and er, or words which are more or less in free variation. For example, most versions of Konráðs saga begin with a statement along the lines of Það er upphaf þessarar frásagnar ('it is the beginning of this narrative'), but the word for narrative varies fairly freely, alternatives to frásögn (genitive singular frásagnar) being saga and frásaga (along with a few manuscripts where this character is not represented at all). Meanwhile, the end of each saga explains that Konráður had children with a sentence like þau Konráður og Matthildur áttu tvo sonu ('Konráður and Matthildur had two sons'), but the verb used varies fairly freely between eiga (past 3rd person plural áttu) and geta. Figure 9 repeats Zitzelsberger's stemma, but for each manuscript I surveyed, the stemma shows the readings for these two characters only.
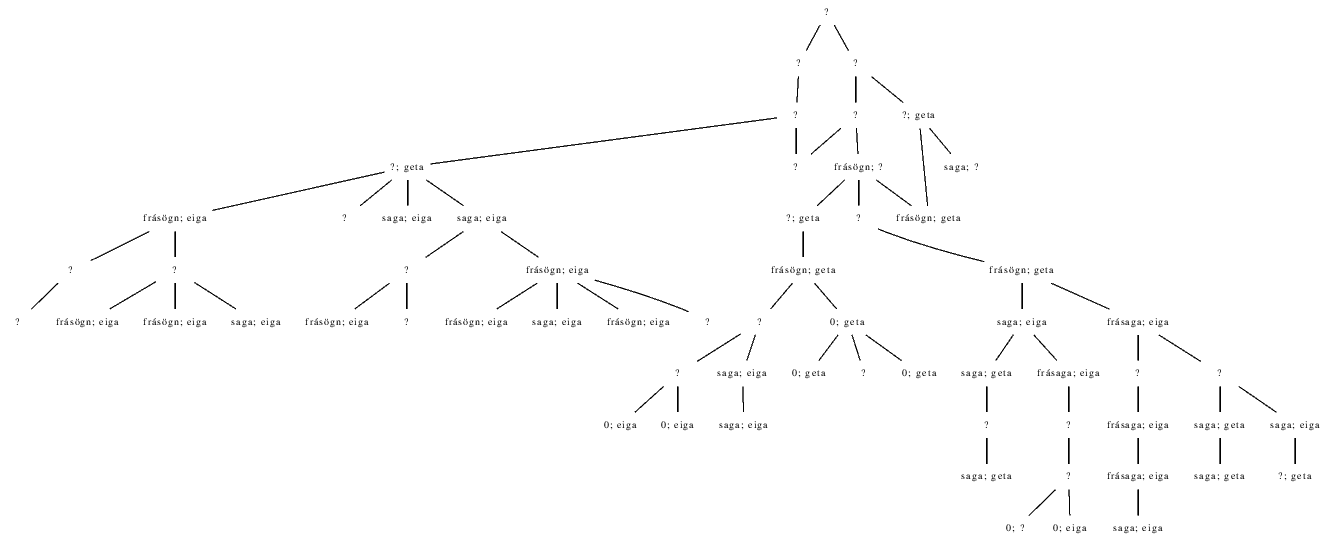 |
Figure 9: Zitzelsberger's stemma, showing variants on frásögn and eiga. |
Unless Zitzelsberger's stemma is badly wrong, or fails to recognise extensive conflation of exemplars, this demonstrates fairly free variation in Icelandic between the terms studied: thus geta becomes eiga and eiga becomes geta independently at several points in the tradition. Traditionally, these variants would therefore be discarded as text-critical evidence. But a glance at the diagram also shows that a scribe is still considerably more likely to copy his exemplar than to switch word. Thus the balance of probability is that one manuscript using the verb eiga was copied from another using the same verb. Taking my spreadsheet of 35 texts, I used Pars to construct a stemma of Konráðs saga using only these two variants, shown in Figure 10.
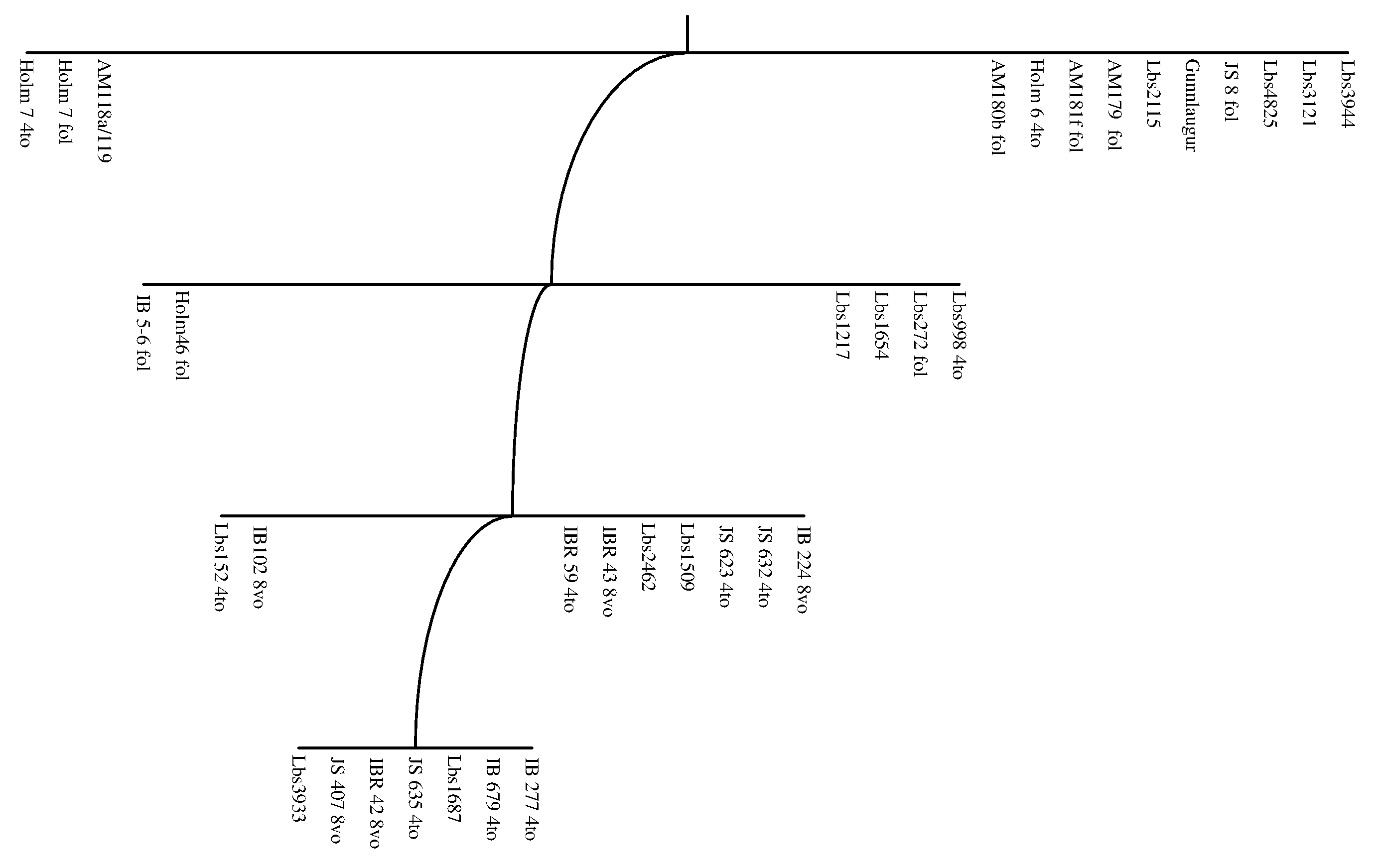 |
Figure 10: Pars stemma constructed using only the characters frásögn and eiga. |
I did follow convention, however, in disregarding spelling variation. This decision was based on the assumption that, whereas in literatim copying, spelling variation can be important, spelling would be too susceptible to independent common innovations to be useful for stemmatic analysis in the scribal tradition of Icelandic sagas. However, future experimentation might prove the usefulness of spelling variation.
My own analysis of the data, building on my Pars analyses, and involving the construction of a draft HTML stemma like the HTML rendering of Zitzelsberger's stemma presented in section 2.1, took into account manuscript dating (since an older manuscript cannot be copied from a younger one) along with an ability to make contextual judgements about the likelihood of one reading producing another (taking account, for example, of the likelihood of misreading, or the distinctive limitations imposed on a copyist by an omission in his exemplar). This made the analysis much finer than Pars's, though similar in its fundamental principles. I have not created an HTML version of my independent stemma, but a final HTML stemma incorporating those of my readings which I believe are superior to Zitzelsberger's is presented as Figure 12 (which shows my precise reasoning in all cases).
The outcome of my filiation of the texts of Konráðs saga was a stemma fundamentally similar to Zitzelsberger's: removing from Zitzelsberger's stemma those manuscripts not included in my survey, my stemma scores 87.5% against Zitzelsberger's. This provides independent verification of Zitzelsberger's own work, and, in turn, indicates that the small samples with which I worked did not prevent the production of a stemma similar to that achieved by traditional (albeit unstated) methods. Still, 87.5% is still far from identical, so the differences require detailed examination:
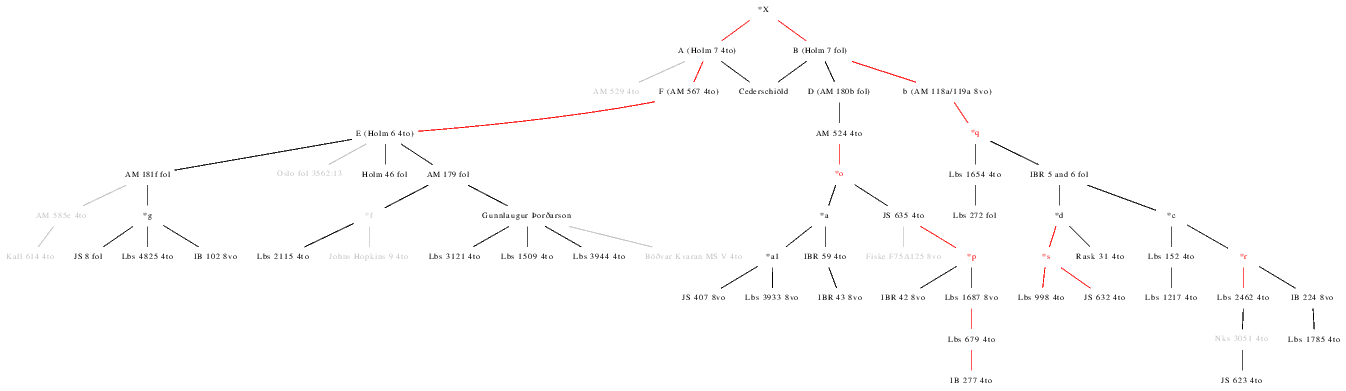 |
Figure 11: My independent stemma of Konráðs saga, based on the transcribed passages. |
At the top of the stemma, my sampling was too limiting: because most of the earliest manuscripts of Konráðs saga are fragmentary, with either the beginning or the end missing, there was too little overlap to produce a reliable stemma, or in some cases any rational stemma at all (cf. Slay 1997, which does not attempt to reconstruct the top of Mírmanns saga's stemma). Stockholm perg 7 4to (Zitzelsberger's A), of which the end survives, and Stockholm perg 7 fol (Zitzelsberger's B), of which the beginning survives, were arbitrarily rooted as separate descendants of a lost original, though in theory B, the later of the two manuscripts, could have been rooted as a child of A. AM 529 4to, which offers a fragment only of the first section sampled, I did not try to filiate at all. The fragment AM 567 4to (Zitzelsberger's F) was rooted as a descendant (rather than a nephew) of A, and the parent (rather than the sibling) of Stockholm perg 6 4to. It was, however, self-evident that the sampling of these fragmentary manuscripts was insufficient, and that the top of my stemma could be no more than a working hypothesis from which to develop a more reliable stemma on the basis of targeted transcription. Though no doubt wrong, my stemma did produce known unknowns.
While easily recognising the close relationship between the manuscripts Lbs 679 4to and ÍB 277 4to, which share a very large number of innovations, my sample was insufficient to place these in the stemma, or to be sure whether one was copied from the other or whether they derived independently from a common ancestor. It was evident that they were broadly more similar to the tradition descending from Stockholm, Royal Library, perg 7 fol than the one descending from Stockholm perg 6 4to, but distinctive readings within this were hard to find. The closest distinctive comparisons which I found in my sample were with two innovations attested in Lbs 1687 8vo: all three begin Ríkharður hefur keisari heitið, and all three introduce Jarl Roðgeir in a distinctively similar way: Lbs 1687 8vo says `Jall var i Rikinu er Rodgeir hét', while Lbs 679 4to and ÍB 277 4to give Jarl var í Ríki keisara er Roðgeir hét. However, while suggestive, these similarities could easily have arisen independently; moreover, Lbs 1687 8vo is probably later (c. 1850) than Lbs 679 4to and ÍB 277 4to (both 1834 or thereabouts), while Lbs 679 4to records that its exemplum was written in 1750 (Zitzelsberger 1981, 172 n. 22). Zitzelsberger was instead able to associate them (somewhat tentatively) with the other branch of the tradition stemming from Stockholm, Royal Library, perg 7 4to, and with Lbs 1654 4to and the almost identical Lbs 272 fol in particular (1981, 160--61).
As with the top of the stemma, the problems arising here from sample sizes produced known unknowns: it was clear that further, targeted research was required reliably to ascertain the texts' positions in the stemma. The small sample did not produce seriously misleading results, but rather would have facilitated further research.
A major difference between my stemma and Zitzelsberger's was in the filiation of Lbs 2462 4to. Zitzelsberger simply said `2462 (1801) and its copy, 623, derive from 1654', unfortunately offering no rationale for this (1981, 162). My sample, however, associates Lbs 2462 4to with the family of Lbs 1654 4to's sister-manuscript ÍBR 5--6 fol, via ÍB 224 4to. The weight of evidence can most easily be summarised by reproducing the relevant sections of my HTML version of Zitzelsberger's stemma and my final HTML stemma. If we read Lbs 2462 4to as a descendant of Lbs 1654, we must reckon on it making a large number of changes to its exemplar. As in the HTML stemmas, I rubricate text which shows a change from the putative exemplar, and mark omissions with `{...}':
Lbs 1654 4to
1. [f. 1r]
Þad er uphaf þessarar frasøgu ad eirn Gofug$[...] sare Riede firir Saxlande sa er Rÿgardur hiet, hann $[...] $$lld ÿfir ǫllum heime firir sunnan haf, hann var milldur og uins$[...] vel ad sier giǫr, hann var sigursæll j. orustum, vitur og sniall j m$[...] ödur og forsiäll. hann var kuongadur madur, og er ei nefnd kona han$[...] attu ij bǫrn, hiet Konradur son þeirra enn Siuilla dötter. þat var [...] [...]$iætum giǫrt huad fǫgur þau voru af ǫllum þeim þau säu, Konradur $$[...] [...]ldre þeirra sÿskÿna. Rodgeyr hiet einn gǫfugur Jall, hann var hin[...] [...]pekingur og hinn beste klerkur, hann kunne allra þiöda tungur nälega J h$[...] [...]numm, og so er ä kuedid, ad hann kunne allt þad sem madur matte kunna [...] [...]$ þessum heime,
2. [f. 20v]
þau konräd & Matth vntuzt mikid, og ättu ij. Sonu, hiet annar Vilhiälmur, enn annar Heynrikur, Epter miklagardz konginn töku þau Rÿke & vntu þess vel og leinge, Vilhialmur var sendur til Saxlandz & vard mikill Hǫfdingi, Konräd hiellt virdingu Sinne og Rÿke, & þőtte hinn vitrazte & hinn frægaste kongur alla æfe / hann liet þad giǫra til ägiætis sier ad hann liet fÿlz leggina grafa, Og Gulle J Renna, og setia vÿda gÿmsteinum, og liet þar giǫra branda firir hallar [f. 21r] hallar dÿrumm sÿnumm, hann riede fyrer Miklagarde medann gud liede honum lijfdaga til, eptir hanz daga vard Heinrekur Stőlkőngur, og stÿrde vel & stillelega Sÿnu Rÿke, og hefur mikid af viturleik & vaskleik fodur sijnz hann ätte sier þann son er kÿrielax hiet, hann var vitur og vinsæll, og vel ad sier þad kalla menn, ad borg su Mune bigd Hafa verid firir ønduerdu, er Konräd sőcte[?] ste inana til, og Mune ormar, og Eiturkuykendj monnum Eitt hafva J þeim stad, Enn Kirrielax kőngur, Riedj lej= nge firir synu rijke, og eru margar Merkeligar sǫgur fra komnar, þo ad þad sie Ey gre$nd J þeßare frä sǫgu, Enn eirn Köngur fann hana skrifada, á Eynu stræde med þeßumm hætte sem nu eru fröder menn vanir ad seigia sydann, og prÿdde þennann köng Rausnarseme {...} /: og er hier Nu lokid þessare frasogu vmm Conrad Keisarason. ~ Anno. MDC.LXXXII. XXIII. Octobris.
Lbs 2462 4toIt is clear at a glance that if Zitzelsberger's filiation is correct, Lbs 2462 4to must be a highly innovative rendering. But some of these changes are attested earlier in the *c branch descending from ÍBR 5--6 fol. To give the most important examples, in section 1 the *c manuscripts call Konráður's sister Similia instead of variants containing v, like 1654's `Siuilla'; they call Roðgeir an ágætur jarl instead of a göfugur jarl; they denote the languages which Roðgeir speaks with tungumál instead of tungur; and they omit the following description of his learning. In section 2, they re-order the description of Konráður's engraving of the elephant-leg. More specifically again, Lbs 2462 4to shares a few further readings only with ÍB 224 8vo: for example, in section 2, Konráður's son Henríkur owes his wisdom not to his father, but to his mother; and snakes have not only eaten the people of a city, but lagst so á gullið (`laid themselves upon the gold'). It is hard to believe that these similarities are a fluke reflecting a small sample, and accordingly I have filiated Lbs 2462 4to and ÍB 224 4to as the children of a lost common ancestor *r. Zitzelsberger must have made a mistake. Indeed, some confusion regarding this branch is also evident in his claim that `1785 (1833) and the badly tattered 1217 (1817) are direct copies of 152 and 224, respectively' (1981, 162): as Zitzelsberger's own discussion and stemma show, he meant that Lbs 1785 4to was a copy of Lbs 224 4to, and Lbs 1217 4to a copy of Lbs 152 4to, not the other way round, and my analysis agrees with this. Zitzelsberger's notes may have been incomplete or simply have included some mistakes regarding this section of the stemma. It seems likely, then, that Zitzelsberger's filiation of Lbs 2462 4to with Lbs 1654 4to was simply an error.
1. [f. 119r]
Þad er Upphaf þessarar sǫgu ad einn gǫfugur keisare réde fyrir Saxlande er Rgardr hét, hann átte vald yfir ǫllum heimi fyrir sunnan haf, hann var mildr og vinsæll, og vel ad sér giǫr um alla hlut$ {...}; hann var kvongadur {...}, og er ej Drottníng hans nefnd, þau áttu 2 Bǫrn, og het Conrád son hans, enn Similia Dóttir, þau voru ágætum listum búin, og miǫg fǫgr álitin af ǫllum þeim er þau sáu, Conrád var eldre þeirra systkina; Rodgeir hét einn ágætr Jall, hann var hinn meste spekíngr, og {...} beste klerkr, hann kunni allra þioda Túngumál í ǫllum heimi,
2. [f. 144r]
þau Conrád og Matthildr unntust mikid vel, og gátu tvo sonu, hét annar Vilhiálmur, enn ann- ar Hinrik eptir Miklagards kongi, tóku þeir Ríki, og nutu[?] þeß vel og lengi, Vilhiálmr var sendr til Saxlands, og vard þar mikill hǫfdíngi, Conrád hélt virdíngu sinni, og Ríki, og þókte hinn frægaste {...} alla æfi, hann lét grafa Fíls leggina til ágætis sér, og gulli vída renna og gimm- steinum setia, og lét þaraf giǫra Branda fyrir sínum hallar- dyrum, hann réde fyrir Miklagardi medan hans lífdagar endtuste[?], enn eptir hans dag var Hinrik son hans stólkongr í Miklagardi, og stírdi vel og lengi Ríki sínu, því hann hafdi mikid af viturleik {...} módr sinnar og $enisti[?] fǫdr síns, hann átti {...} þann son er Cyrielax hét, hann var vitr og vinsæll, og vel ad sér, þad kalla menn ad borg sú hafi biggd {...} verid fyrir ǫndverdu er Fadir hans sókti steinana í, og munu þar[?] Ormar og Eitr kvikindi mǫnnum eidt hafa í þeim stad, og lagst so á gullid; enn Cyrielax {...} réde lengi fyr- -ir sínu Ríki, og eru margar merkilegar sőgur frá honum komnar, þó {...} ej sér[?] hér greindar. og endast h;er sagan af þeßum frægakappa Conrádr= [f.144v] Keisara Syni, samt af þeim slæga svikara Rodbert. Historia hæc die decimo tertio mense Januari, anno autem Xi Millesimo octingenteprimo[?] primo scripta fuit. M: ~ A:
A general difference between my stemma and Zitzelsberger's is that---setting aside our necessarily different handlings of the top of the stemma---we often reconstruct lost manuscripts slightly differently. Zitzelsberger sometimes inferred a lost manuscript simply on the grounds that dramatic changes between an exemplar and a copy are best accounted for by a damaged or illegible intermediary copy. This may sometimes be true, but it reflects an assumption which runs through Zitzelsberger's stemmatic work that copyists ought to try, and were trying, to copy literatim. Thus Zitzelsberger originally argued for a lost manuscript *f between AM 179 fol and Lbs 2115 4to because Lbs 2115 changes Roðgeir from a berserkur (`berserk') to a bartskeri (`barber-surgeon'; the example conveniently falls within my transcribed sections). Understanding this as a mistake, Zitzelsberger could not see how it could have arisen from the clearly written AM 179 fol and so inferred a lost manuscript. But I see no reason why this should not be a deliberate change, and omitted *f from my stemma. (In the event, however, Zitzelsberger's later discovery of Johns Hopkins 9 4to, not included in my study, seems to have proved the existence of *f for other reasons, so I have retained it in the final stemma). Likewise, we can see the changes between Stockholm, Royal Library, perg 7 fol (Zitzelsberger's B) and AM 118a/119a 8vo (Zitzelsberger's b) simply as rewritings---at least in the passages I have transcribed---without needing to posit an intervening damaged or illegible *b, as Zitzelsberger did. Finally, Zitzelsberger inferred a lost manuscript *d between ÍBR 5--6 fol and Rask 31 4to simply because he perceived many mistakes in Rask 31 and thought it unlikely that the scribe of that manuscript would have introduced them. He then saw Lbs 998 4to as a direct descendant of Rask 31. I would not have inferred *d on the grounds that Zitzelsberger did; but did perceive a case for Rask 31 and Lbs 998 4to each descending from a lost common ancestor. The case is slight, however, and more analysis would be needed to confirm the filiation.
In some cases, however, I posit more lost manuscripts than Zitzelsberger. In one case, *s, this is simply because the putative exemplar (Lbs 998 4to) is probably later (the earlier nineteenth century) than the putative copy (JS 632 4to, whose title page dates it to 1799--1800; Wick 1996, 258, 268): this observation simply reflects our gradually accumulating information on manuscript provenance. Usually, though, my greater predilection for inferring lost manuscripts suggests that I am less likely to ascribe similarities between manuscripts to independent common innovation than Zitzelsberger was. This is a subjective judgement, but might reflect my experience of systematically reconstructing lost texts in my HTML stemma: this method of working encourages the precise identification and encoding of variants, and tends to reveal when two similar manuscripts can not in fact be in a parent-child relationship. The reasoning behind my reconstructed manuscripts can be seen easily through my final HTML stemma and the reader will be able to judge for themselves whether the variants demand these reconstructions.
In one case, Zitzelsberger explicitly discounted the possibility of a lost manuscript where I accepted it. Regarding the relationship of AM 118a/119a 8vo to its descendants ÍBR 5--6 fol and Lbs 1654 4to, Zitzelsberger wrote (1981, 158) that they
must derive independently of each other either from 118a/119a itself or from a lost intermediate copy of the latter. For the second possibility there is no firm evidence: whatever variants 5 and 1654 introduce are minor and apparently spontaneous.However, it seems clear from my sampling that ÍBR 5--6 fol and Lbs 1654 4to show seven common innovations, each quite small but collectively striking. In theory, Lbs 1654 4to could be the exemplar of ÍBR 5--6 fol, but it was copied two years later. We must, therefore, take Zitzelsberger's second option, reconstructing a lost manuscript source for ÍBR 5--6 fol and Lbs 1654 4to. This may represent a case where the detailed focus on a small sample, rather than a more cursory examination of a bigger sample, encourages a more rigorous assessment of the evidence.
On the other hand, my inference of the manuscript *p, on subsequent checking, proved unnecessary. This is a good example of human error, emphasising the value of transparent data and rigorous checking.
For some kinds of research, it is not very important whether one manuscript is the exemplar of the other, or whether they are both descended from a lost common ancestor; and there will always be circumstances in which this cannot be discovered either way. Still, my detailed analyses and reconstructions of lost texts do suggest the power of such close readings for helping us to identify the existence of lost manuscripts. Of course my samples are much too small to make any claim to comprehensiveness: fuller samples would presumably uncover more evidence for lost manuscripts. This could be valuable, helping us to address the vexed question of what proportion of our manuscripts actually survive (cf. the debate in Cisne 2005a, b; Declercq 2005; for Nordic studies see Driscoll 2003, 259 and Haugen 2012). The sampling approaches adopted here will not maximise the potential of our evidence for positing lost manuscripts, but do indicate the power of rigorous reconstruction of stemmas making use of all variants in a short passage.
Two manuscripts of Konráðs saga unknown to Zitzelsberger, now held in Winnipeg, were first described by Einar Gunnar Pétursson and Viðar Hreinsson in 1994, and were then examined in detail by Katelin Parsons in 2010. Having brought these copies of Konráðs saga to my attention, Parsons has provided descriptions of the manuscripts here, for their inclusion in the saga's stemma.
A collection of eight legendary and romance sagas. Konráðs saga keisarasonar (Sagann af CONRAD-KEISARA syne og RODBERT SVIKARA) on folios 22r--46r. Other sagas in the manuscript are: Sigurðar saga fóts, Jarlmanns saga og Hermanns, Dínus saga drambláta, Gjafa-Refs saga, Hrólfs saga Gautrekssonar, Fertrams saga og Plató and Úlfs saga Uggasonar.
Early/mid 19th century; i + 157 + i leaves; vellum binding over wooden boards (partially exposed).
The provenance of this manuscript is unknown, but what may be an owner’s statement is written in a younger hand on the front flyleaf: ‘Þessi bók er samhallan[di] Fjandans þvættíngur hana á með réttu bóndinn Benedikt Jónss[on] á Síðu í Vididal’ (‘This book is damned rubbish straight through; it is the rightful property of farmer Benedikt Jónsson of Síða in Víðidal’).
Despite being identified here as Jónsson, the farmer at Síða in Víðidal, located in the district of Húnavatnssýsla, was in fact Benedikt Björnsson (1807--62), who moved to Síða between 1850 and 1855.
Two names written on the book’s inside cover and front flyleaf indicate that the book probably left Iceland in 1874, when Jósef Guðmundsson and his stepdaughter Guðbjörg Baldvinsdóttir emigrated from the Kelduland farm in Húnavatnssýsla to Kinmount, Ontario, accompanied by Jósef’s wife (Guðrún Rafnsdóttir) and Guðbjörg’s sister (Helga Baldvinsdóttir). Jósef Guðmundsson and his family (the Goodmans) were among the first group of immigrants to settle in New Iceland in 1875.
The manuscript was donated to the Jón Bjarnason Academy Library in Winnipeg at an unknown date. When the school closed in 1940, the Icelandic manuscripts in its collection were sent to the University of Manitoba, where they are currently housed in the Icelandic Collection of Elizabeth Dafoe Library.
A fragment (8 leaves) containing the final page of Sigurgarðs saga frækna (f. 1r) and the beginning of Konráðs saga keisarasonar (ff. 1v--8v). At the bottom of folio 1r is a decorative pen-drawn vignette, with a number of tiny birds and animals, below which the date 1838 is written.
The MS was formerly in the collection of the Jón Bjarnason Academy Library (see above); its provenance is otherwise unknown.
ISDA JB6 1 4to presents an innovative and much abbreviated version of the saga, but, as the data in the revised HTML stemma in section 5.1 show, seems clearly to be a descendant either of NKS 3051 4to or its near-identical descendant JS 623 4to. Fuller, targeted sampling of the manuscripts would presumably resolve this; I have assumed for now that JS 623 4to and the Winnipeg manuscript are siblings.
ISDA JB3 6 8vo is fragmentary, lacking the end of the saga. As mentioned in section 2.2, this emphasises the limitations of my sampling method. However, even this small sample shows that the saga is most closely related to Lbs 1785 4to. It might be a copy, but there are a couple of small points on which ISDA JB3 6 8vo is closer to the ancestor of Lbs 1785 4to; these might be coincidental, but I considered them significant enough to reconstruct yet another lost parent manuscript, *t. Fuller sampling would help to determine whether this was the best decision.
These manuscripts were included in my study at a relatively late stage, after the completion of my revisions to Zitzelsberger's stemma. But the inclusion of annotated transcriptions in my HTML stemma of Konráðs saga made filiation quick and easy---in total, half an hour's work for the two new manuscripts---emphasising the value of this mode of publication. It would have been possible for any researcher, even with no familiarity with the saga, to filiate these new manuscripts in the same way.
Combining Zitzelsberger's findings with my corrections and the new manuscripts, I suggest the current best stemma of Konráðs saga in Figure 12, offering both traditional and HTML formats:
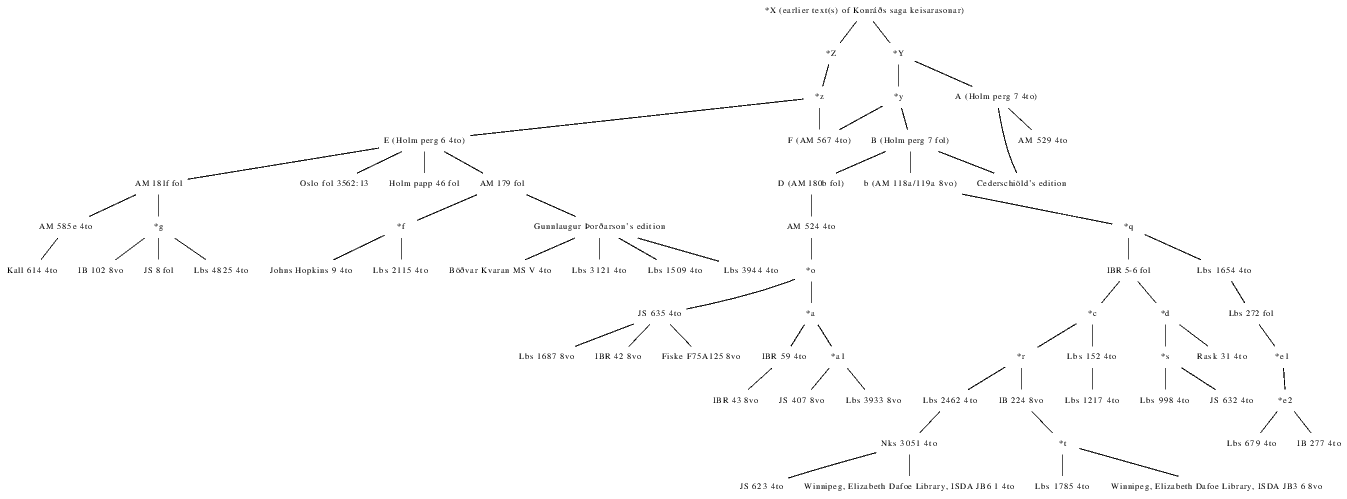 |
Figure 12. The revised stemma Konráðs saga. |
Zitzelsberger did not discuss his stemmatic methodology in detail, and if all that my arguments here achieve is to provoke explicit debate and interdisciplinary research on sampling in stemma studies, then to my mind that will represent significant progress. Zitzelsberger's work is, however, presumably representative of other scholars who have worked within the intellectual community surrounding the Arnamagnæan manuscript collections. I have tested Zitzelsberger's stemma of Konráðs saga keisarasonar against a small, clearly defined, and published sample of data. Our results are very similar. Since our stemmatic analyses were independent, this is an encouraging sign that our methods are at least consistent and rigorous. The similarity also implies one of two further conclusions; it is hard to know which is right, but both are encouraging in their different ways. Either
There are, however, moments in my analyses where the small size of the samples makes it hard confidently to filiate manuscripts. This is particularly important when the fragmentary state of manuscripts means that too little of their text is sampled. However, in these cases, the research produced known unknowns, which could facilitate targeted and efficient further investigation.
There are also aspects of my analyses where I have found a case for arguing that Zitzelsberger was wrong. This is salutory: we all make mistakes in textual filiation, but it is rare that any scholar returns to check the laborious stemmatic work of a predecessor. However, the innovations in this article at least point the way to modes of publication which will make it more likely that other scholars will check our work and spot our mistakes.
Relatively small samples are not a panacaea for swift stemmatic analysis. My transcriptions took around 27 hours, and my encoding of a large proportion of this data for computer analysis around 10. The subsequent human analysis of this material, however, was still a long and gradual process. But an effort to analyse complete texts, in the manner of much current work in computer-assisted stemmatology, would have taken much longer. Konráðs saga, in Cedersciöld's edition, is around 15,000 words long, so---barring relevant advances in optical character recognition---completing and encoding the transcriptions undertaken here would have taken perhaps forty times longer than it did: getting on for one person-year of full-time work. I have also shown that computer analysis of extremely small samples---just a couple of relatively uninformative characters---might still provide a useful starting point for human analysis.
As I discussed at the beginning of the article, the ultimate point of establishing the complete stemma of a text's surviving attestations is to facilitate the analysis of the texts themselves---whether from literary or linguistic perspectives---and the analysis of the society which produced the texts. One powerful example of the effectiveness of this kind of in-depth analysis is Susanne Arthur's recent work on the seventeenth-century GKS 1002--1003 fol, which builds on stemmatic work as well as detailed social network analyses (2012). The approaches developed in my article point to relatively broad-brush analyses which can underpin and contextualise future deep investigations like Arthur's. Simply as a pointer towards the kinds of study of post-medieval Icelandic scribal culture which a fuller understanding of manuscript transmission can produce, I glance here at the spatial distribution of the manuscripts of Konráðs saga. Little work of this kind has ever been undertaken, and still less with detailed reference to manuscripts' filiation.
The information of library catalogues, supplemented and amended by Zitzelsberger's publications and handrit.is, allows us to localise the copying of twenty-three Icelandic manuscripts, mostly descendants of Stockholm, perg 7 fol (Zitzelsberger's B). Taken on its own terms, the distribution of these manuscripts shows a weighting towards the north and west which is well attested, albeit as yet little understood, but does not tell us much more (see Figure 13).
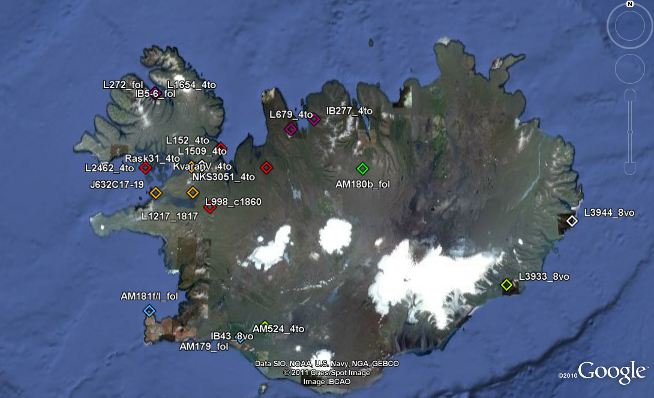 |
Figure 13. The spatial distribution of Konráðs saga manuscripts. |
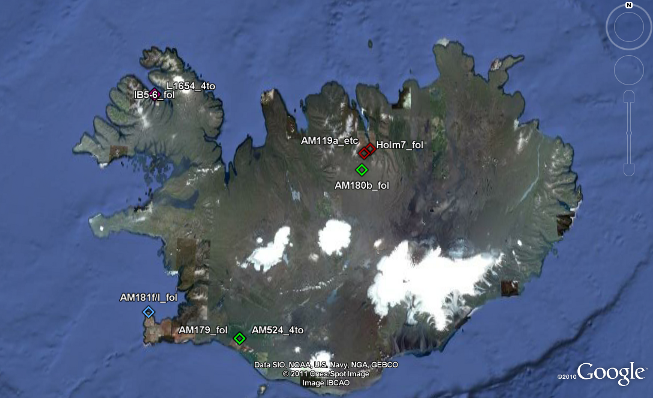 |
Figure 14. The spatial distribution of early Konráðs saga manuscripts. |
However, as I discussed in section 1.3, the patterns of Icelandic manuscript production (or at least survival) seem to have changed markedly around the end of the seventeenth century. Some nineteenth- and twentieth-century manuscripts, while fairly closely related textually, are widely dispersed in space. This is true of the three localisable manuscript copies of Gunnlaugur Þorðarson's 1859 editio princeps of Konráðs saga (two of which are by the same man, Magnús Jónsson í Tjaldanesi), which presumably reflects the broad distribution of the printed text (mapped in white); and Lbs 3933 8vo and ÍBR 43 8vo, related to one another rather distantly, the former appearing, unusually, in the East of Iceland. Without further investigation, it is hard to know what to make of these distributions, but they are if nothing else different from the seventeenth-century pattern of scribal centres.
Clear distribution patterns emerge, however, for the eighteenth- and nineteenth-century manuscripts descending from AM 118a/119a 8vo (Zitzelsberger's b), a large proportion of which are localisable. It appears that from around the scribal centre of Hólar in Eyjafjörður, a descendant of AM 118a/119a 8vo's Konráðs saga (given on the stemma in section 5.1 as *q) came to the Westfjords in the seventeenth century. This text was copied into Lbs 1654 4to and ÍBR 5--6 fol, which have been associated with the region's great aristocrat, merchant and scholar Magnús Jónsson í Vigur. Thus far, the distribution fits the seventeenth-century pattern described above. The eighteenth- and nineteenth-century descendants of these manuscripts, however, show a more diffuse but still relatively local distribution:
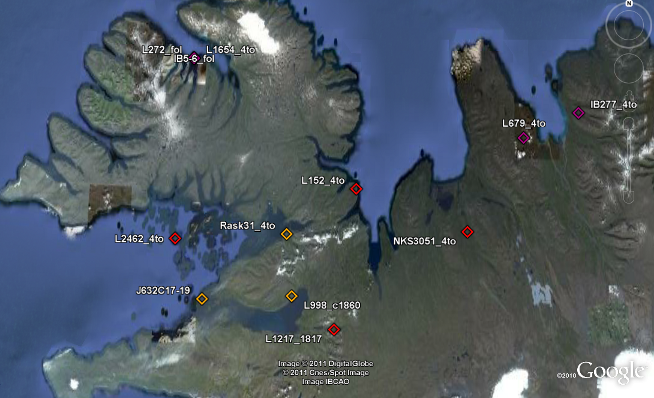 |
Figure 15. Focused spatial distribution of eighteenth- and nineteenth-century Konráðs saga manuscripts. |
Needless the say, the patterns identified here demand further exploration. One avenue for this is more detailed research into Konráðs saga manuscripts: further work to localise manuscripts, and to trace their movements after their production, in combination with prosopographical and social-network analyses of their scribes and readers. However, the patterns can also be explored by expanding our dataset to include other stemmas of other sagas---many of which will co-occur alongside Konráðs saga in the manuscripts already mapped here. The methods which I have outlined here will allow us to achieve this more efficiently, and more swiftly.
Arthur, Susanne Miriam. 2012. The importance of marital and maternal ties in the distribution of Icelandic manuscripts from the Middle Ages to the seventeenth century. Gripla 23: 201--33. http://www.academia.edu/2323169/The_Importance_of_Marital_and_Maternal_Ties_in_the_Distribution_of_Icelandic_Manuscripts_from_the_Middle_Ages_to_the_Seventeenth_Century.
Bodard, Gabriel and Jauan Garcés. 2010. Open source critical editions: a rationale. In Digital research in the study of classical antiquity, ed. Gabrel Bodard and Simon Mahony, pp. 83--98. Aldershot: Ashgate. http://operi.us/pdftribute/pdfs/Bodard-Garces_2009_Open-source-digital-editions.pdf.
Boot, Peter. 2007. Mesotext: framing and exploring annotations. In Learned love: proceedings of the Emblem Project Utrecht Conference on Dutch Love Emblems and the Internet (November 2006), ed. Els Stronks and Peter Boot, pp. 211--25. DANS Symposium Publications, 1. The Hague: DANS---Data Archiving and Network Services. http://emblems.let.uu.nl/static/images/project/learned_love_211-225.pdf.
Bordalejo, Barbara. 2003. The phylogeny of the order in the `Canterbury Tales'. Unpublished Ph.D. thesis, New York University. http://www.bordalejo.net/theses.html.
Brewer, Charlotte. 1996. Editing `Piers Plowman': the evolution of the text. Cambridge Studies in Medieval Literature, 28. Cambridge: Cambridge University Press.
Broberg, Sven Grén (ed.). 1909--12. Rémundar saga keisarasonar. Samfund til udgivelse af gammel nordisk litteratur, 38. Copenhagen: Møller.
Cederschiöld, Gustaf (ed.). 1884. Fornsögur Suðrlanda. Lund: Gleerup.
Cisne, John L. 2005a. How science survived: medieval manuscripts' `demography' and classic texts' extinction. Science 307: 1305--7. DOI: 10.1126/science.1104718.
Cisne, John L. 2005b. Response to comment on `How science survived: medieval manuscripts' "demography" and classic texts' extinction'. Science 310: 1618. DOI: 10.1126/science.1117724.
Collín, H. S. and C. J. Schlyter (eds). 1827--77. Corpus iuris Sueo-Gotorum antiqui: Samling af Sweriges gamla lagar, på Kongl. Maj:ts. nådigste befallning. 13 vols. Stockholm: Haeggström. books.google.co.uk/books?id=-q8-AAAAcAAJ&.
Davíð Ólafsson. 2009. Wordmongers: post-medieval scribal culture and the case of Sighvatur Grímsson. Unpublished Ph.D. thesis, University of St Andrews. http://hdl.handle.net/10023/770.
Declercq, Georges. 2005. Comment on `How science survived: medieval manuscripts' "demography" and classic texts' extinction'. Science 310: 1618. DOI: 10.1126/science.1117462.
Driscoll, Matthew James. 1997. The unwashed children of Eve: the production, dissemination and reception of popular literature in post-Reformation Iceland. Enfield Lock: Hisarlik Press.
───. 2003. Fornaldarsögur norðurlanda: The Stories that Wouldn't Die. In Fornaldarsagornas struktur och ideologi, ed. Ármann Jakobsson, Annette Lassen and Agneta Ney, 257--67. Nordiska texter och undersökningar, 28. Uppsala: Uppsala Universitet.
───. 2005. Late prose fiction (lygisögur). In A companion to Old Norse-Icelandic literature and culture, ed. Rory McTurk, 190--204. Oxford: Blackwell.
───. 2010. The words on the page: thoughts on Philology, Old and New. In Creating the medieval saga: versions, variability, and editorial interpretations of Old Norse saga literature, ed. Judy Quinn and Emily Lethbridge, 85--102. The Viking Collection, 18. Odense: University Press of Southern Denmark. http://www.staff.hum.ku.dk/mjd/words.html.
Felsenstein, Joseph. 1986--2008. Pars---discrete character parsimony. Version 3.69. http://evolution.gs.washington.edu/phylip/doc/pars.html.
───. 1989. PHYLIP---Phylogeny Inference Package (version 3.2). Cladistics 5: 164--66. DOI: 10.1111/j.1096-0031.1989.tb00563.x.
───. 2005. PHYLIP (Phylogeny Inference Package). Version 3.6. http://www.phylip.com.
Glauser, Jürg. 1994a. Spätmittelalterliche Vorleseliteratur und frühneuzeitliche Handschriftentradition. Die Veränderungen der Medialität und Textualität der isländischen Märchensagas zwischen dem 14. und 19. Jahrhundert. In Text und Zeittiefe, ed. Hildegard L. C. Tristram, 377–-438. ScriptOrialia, 58. Tübingen: Narr.
Glauser, Jürg. 1994b. The end of the saga: text, tradition and transmission in nineteenth- and early twentieth-century Iceland. In Northern antiquity: the post-medieval reception of Edda and saga, ed. Andrew Wawn, pp. 101--41. Enfield Lock: Hisarlik Pres.
Hall, Alaric. 2005. Changing style and changing meaning: Icelandic historiography and the medieval redactions of Heiðreks saga. Scandinavian Studies 77: 1--30. http://eprints.whiterose.ac.uk/5599/.
Hall, Alaric, Haukur Þorgeirsson, Patrick Beverley, et al. 2010. Sigurðar saga fóts (The saga of Sigurðr Foot): a translation. Mirator 11: 56--91. http://www.glossa.fi/mirator/pdf/i-2010/sigurdarsagafots.pdf.
Hall, Alaric. Forthcoming. The stemma of Sigurgarðs saga frækna.
Hall, Alaric and Sheryl McDonald. Forthcoming. The stemma of Nikulás saga leikara (the longer recension).
Hanna, Ralph, III. 1996. The manuscripts and transmission of Chaucer's Troilus. In Pursuing history: Middle English manuscripts and their texts. 115--29. Stanford, CA: Stanford University Press (repr. from 1992. The idea of medieval literature: new essays on Chaucer and medieval culture in honor of Donald R. Howard, ed. James M. Dean and Christian K. Zacher, 173--88. Newark: University of Delaware Press.
Hanna, Ralph. 2000. The application of thought to textual criticism in all modes---with apologies to A. E. Housman. Studies in Bibliography 53: 163--72. http://etext.lib.virginia.edu/bsuva/sb/.
Haugen, Odd Einar. 2008. The Menota handbook: guidelines for the electronic encoding of medieval nordic primary sources, version 2.0, TEI P5 conformant. Bergen: The Medieval Nordic Text Archive. http://www.menota.org/guidelines/index.page.
───. 2012. On the birth and death of medieval manuscripts. In The 15th International Saga Conference: Sagas and the Use of the Past 5th–11th August 2012, Aarhus University. Preprint of Abstracts, ed. A. Mathias Valentin Nordvig and Lisbeth H. Torfing, 149. Aarhus: Department of Aesthetics and Communication, Department of Culture and Society, Faculty of Arts. http://sagaconference.au.dk/fileadmin/sagaconference/Preprint-online.pdf.
Jónas Kristjánsson (ed.). 1960. Dínus saga Drambláta. Riddarasögur, 1. Reykjavík: Háskóli Íslands.
Jónas Kristjánsson (ed.). 1964. Viktors saga ok Blávus. Riddarasögur, 2. Reykjavík: Handritastofnun Íslands.
Kalinke, Marianne E. and P. M. Mitchell. 1985. Bibliography of Old Norse–Icelandic romances. Islandica, 44. Ithaca: Cornell University Press.
Kalinke, Marianne. 1994. Víglundar saga: An Icelandic bridal-quest romance. Skáldskaparmál 3: 119–-43.
Lansing, Tereza. 2011. Post-medieval production, dissemination and reception of `Hrólfs saga kraka'. Unpublished Ph.D. thesis, University of Copenhagen.
Larrington, Carolyne, and Peter Robinson (eds). 2007. Sólarljóð. In Poetry on Christian subjects, ed. Margaret Clunies Ross, i, 287--357. Skaldic Poetry of the Scandinavian Middle Ages, 7, 2 vols. Turnhout: Brepols.
Leslie, Helen F. 2012. Younger Icelandic manuscripts and Old Norse studies. RMN: The Retrospective Methods Network Newsletter 4: 148--161. http://www.helsinki.fi/folkloristiikka/English/RMN/current.htm.
McDonald, Sheryl. 2012a. Some Nitida saga manuscript groupings. In The 15th International Saga Conference: Sagas and the Use of the Past. 5th-–11th August 2012, Aarhus University. Preprint of Abstracts, ed. A. Mathias Valentin Nordvig and Lisbeth H. Torfing, 227–-28. Aarhus: Department of Aesthetics and Communication, Department of Culture and Society, Faculty of Arts.
───. 2012b. Variance uncovered and errors explained: an analysis of Nítíða saga in the seventeenth-century Icelandic manuscript JS 166 fol. Digital Philology: A Journal of Medieval Cultures 2: 303--18. DOI: 10.1353/dph.2012.0012.
Misra, Navodit, Guy Blelloch, R. Ravi, et al. 2010. Generalized Buneman pruning for inferring the most parsimonious multi-state phylogeny. In Research in Computational Molecular Biology: 14th Annual International Conference, RECOMB 2010, Lisbon, Portugal, April 25--28, 2010. Proceedings, ed. Bonnie Berger, 369--83. Lecture Notes in Computer Science, 6044. Berlin: Springer. http://arxiv.org/pdf/0910.1830.pdf.
Niskanen, Samu. 2009. The Letter Collections of Anselm of Canterbury. Unpublished Ph.D. thesis, University of Helsinki.
Page, R. I. 1960. Gibbons saga. Editiones Arnamagnæanæ, Series B, 2. Copenhagen: Munksgaard.
Pierazzo, Elena. 2011. A rationale of digital documentary editions. Literary and Linguistic Computing 26: 463--77.
Robins, William. 2007. Editing and evolution. Literature Compass 4: 89-120. DOI: 10.1111/j.1741-4113.2006.00391.x.
Robinson, P. M. W. 1989a. The collation and textual criticism of Icelandic manuscripts (1): collation. Literary and Linguistic Computing 4: 100--5. DOI: 10.1093/llc/4.2.99.
───. 1989b. The collation and textual criticism of Icelandic manuscripts (2): textual criticism. Literary and Linguistic Computing 4: 174--81. DOI: 10.1093/llc/4.3.174.
─── and Robert J. O'Hara. 1996. Cladistic analysis of an Old Norse manuscript tradition. In Selected papers from the ALLC/ACH conference, Christ Church, Oxford, April 1992, 115–-37. Research in humanities computing, 4. Oxford: Clarendon Press. http://rjohara.net/cv/1996-rhc.
Roos, Teemu and Tuomas Heikkilä. 2009. Evaluating methods for computer-assisted stemmatology using artificial benchmark data sets. Literary and Linguistic Computing 24: 417--33. DOI: 10.1093/llc/fqp002.
Royal Society, The. 2012. Science as an open enterprise. The Royal Society Science Policy Centre Report, 02/12. London: The Royal Society. http://royalsociety.org/policy/projects/science-public-enterprise/report/.
Salemans, Ben. 2010. The remarkable struggle of textual criticism and text-genealogy to become truly scientific. In Textual comparison and digital creativity: the production of presence and meaning in digital text scholarship, ed. Wido van Peursen, Ernst D. Thoutenhoofd, and Adriaan van der Weel, pp. 113--25. Scholarly Communications, 1. Leiden: Brill.
Sanders, Christopher (ed.). 2000. Tales of knights: Perg. fol. nr 7 in the Royal Library, Stockholm (AM 167 VIβ 4to, NKS 1265 IIc fol.). Manuscripta Nordica: Early Nordic Manuscripts in Digital Facsimile, 1. Copenhagen: Reitzel.
─── (ed.). 2001. `Bevers saga': with the text of the Anglo-Norman `Boeve de Haumtone'. Rit (Stofnun Árna Magnússonar á Íslandi), 51. Reykjavík: Stofnun Árna Magnússonar.
Slay, Desmond (ed.). 1997. Mírmanns saga. Editiones Arnamagnæanæ, Series A, 17. Copenhagen: Reitzel.
Spaulding, Janet Ardis. 1982. Sigurðar saga turnara: a literary edition. Unpublished Ph.D. thesis, University of Michigan.
Spencer, Matthew, Barbara Bordajelo, Peter Robinson, et al.. 2003. How reliable is a stemma? An analysis of Chaucer's Miller's Tale. Literary and Linguistic Computing 18: 407--22. DOI: 10.1093/llc/18.4.407.
Springborg, Peter. 1977. Antiqvæ historiæ lepores---om renæssancen i den islandske håndskriftproduktion i 1600-tallet. Gardar: Årsbok för Samfundet Sverige-Island i Lund-Malmö 8: 53--89.
Sæmundur Bjarnason, Benedikt Sæmundsson, Hafdís Sæmundsdóttir, et al. Netútgáfan. http://www.snerpa.is/net.
Taylor, Gary. 2007. A Game at Chess: general textual introduction. In Thomas Middleton and early modern textual culture: a companion to the collected works, ed. Gary Taylor and John Lavagnino, 712--873. Oxford: Clarendon Press.
Wick, Keren H. 1996. An edition and study of Nikulás saga leikara. Unpublished Ph.D. thesis, University of Leeds. http://etheses.whiterose.ac.uk/1632/.
Zitzelsberger, Otto J. 1980. AM 567, 4to, XVI, 1v: an instance of conflation?. Arkiv för nordisk filologi 95: 183--88.
───. 1981. The filiation of the manuscripts of Konráðs saga keisarasonar. Amsterdamer Beiträge zur älteren Germanistik 16: 145--76.
───. 1983. Six MSS of Konráðs saga unlisted in printed catalogues. Amsterdamer Beiträge zur älteren Germanistik 18: 161--77.
─── (ed.). 1987. Konráðs saga keisarasonar. American University Studies, Series I: Germanic Languages and Literature, 63. New York: Lang.
Þórhallur Vilmundarson and Bjarni Vilhjálmsson (eds). 1991. Harðar saga; Bárðar saga, Þorskfirðinga saga, Flóamanna saga; Þórarins þáttr Nefjólfssonar, Þorsteins þáttr uxafóts, Egils þáttr Síðu-hallssonar, Orms þáttr Stórólfssonar, Þorsteins þáttr tjaldstœðings, Þorsteins þáttr forvitna, Bergbúa þáttr, Kumlbúa þáttr, Stjörnu-Odda draumr. Íslenzk fornrit, 3. Reykjavík: Hið Íslenzka Fornritafélag.
{kind=link}
{kind=link}